

kaggleのコンペに参加した時にノートブックでGPUの選択をしておらず、タイトル記載のエラーが発生し、実際に対応した内容です。
【解決方法】Session optionsタブのACCELERATORプルダウンで「GPU T4 x2」を選択
選択できるGPUはNVIDIA製の「GPU T4 x2」と「GPU P100」と「TPU VM v3-8」がありました。推論に使用するため「GPU T4 x2」を選択しました。
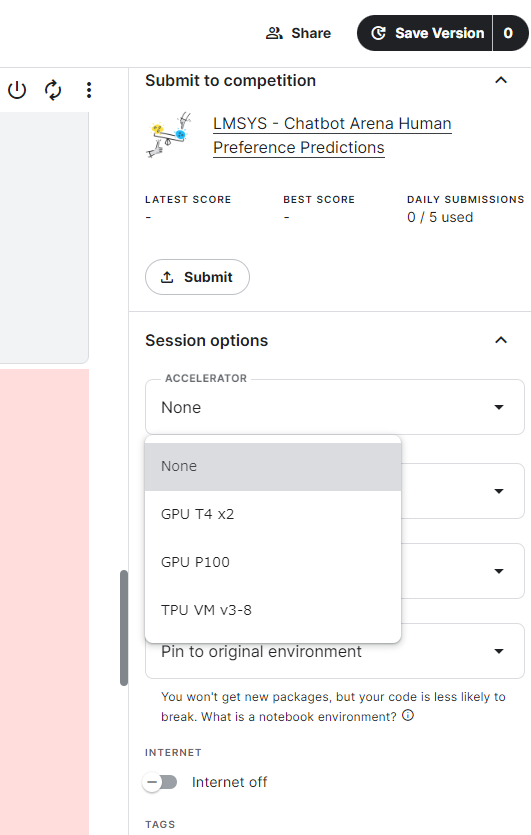
また、違いとしては以下のようになります。CHAT-GPTに聞いてみました。
T4
- アーキテクチャ: Turing
- GPUメモリ: 16GB GDDR6
- CUDAコア数: 2560
- Tensorコア数: 320
- RTコア: 有り (レイトレーシングコア)
- ピークFP32パフォーマンス: 約8.1 TFLOPS
- Tensorコアパフォーマンス: 約65 TFLOPS
- エネルギー消費: 約70W
- 用途: データセンター向けの汎用GPUで、推論、トレーニング、ビデオトランスコーディング、グラフィックスなどに使用されます。
P100
- アーキテクチャ: Pascal
- GPUメモリ: 16GB HBM2 (HBM2の帯域幅はGDDR6よりも高い)
- CUDAコア数: 3584
- Tensorコア数: 無し (TensorコアはVoltaアーキテクチャ以降に導入)
- ピークFP32パフォーマンス: 約10.6 TFLOPS
- エネルギー消費: 約300W (SXM2) / 約250W (PCIe)
- 用途: データセンター向けのハイパフォーマンスコンピューティング (HPC)、ディープラーニングのトレーニング、科学計算などに使用されます。
TPU VM v3-8
- アーキテクチャ: TPU v3
- TPUコア数: 8
- メモリ: 128GB HBM
- ピークTFLOPS: 約360 TFLOPS(推定値、各コア45 TFLOPS)
- エネルギー消費: 一般には公表されていませんが、TPUポッド全体の消費電力は大きいです。
- 用途: ディープラーニングのトレーニングおよび推論、特にTensorFlowとの統合が深いです。
- 特記事項: TensorFlowでの使用に最適化されており、専用ハードウェアとして非常に高い計算能力を提供します。

コメント